강의명: Welcome to Getting Started with Google Kubernetes Engine
## 쿠버네티스란 What are Containers?
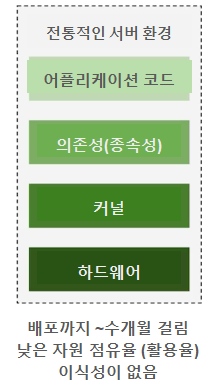
# 전통적인 과거의 서버 환경
어플리케이션은 베어메탈 (bare-metal) 서버에서 구동되었으므로 아래와 같은 셋업 과정이 필요 1. 하드웨어의 설치 2. OS 또는 커널 (kernel)의 설치 3. 어플리케이션 구동에 요구되는 수 많은 의존성에 대한 설치 및 관리 4. 어플리케이션을 이 모든것 위에 설치할 수 있음
문제점 : 이 같은 기나긴 일련의 셋업이 완료된 이후에도 필요한 지속적인 의존성 유지/관리 및 모든것에 대한 싱크를 맞추기가 어려움 ⇒ 해결책으로, VMware가 하이퍼바이저 개념을 도입
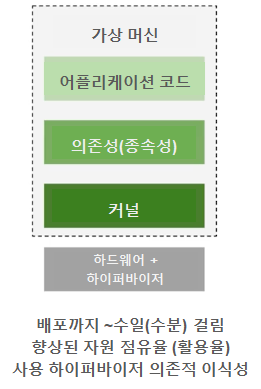
# 하이퍼바이저에 의한 서버 환경
VMware 진영에서, 하드웨어를 하이퍼바이징 하기 위한 방법을 고안 하드웨어를 커널, 의존성, 어플리케이션 으로부터 분리시킨다는 의미
이를 위해서, "하드웨어 하이퍼바이저"라는 계층이 개발되었고, 하드웨어 윗단에 위치한 모든 계층들을 자유롭게 만들어 주었음 즉, 한 단계의 추상 계층이 도입
# 하이퍼바이저에 의한 서버 환경의 문제점 1
하나의 가상머신에, 여러개의 서로 다른 버전으로 운영되는 동일한 어플리케이션의 설치/구동이 불가능 ⇒ 의존성 에러가 속출하고, 여러가지 충돌 상황이 발생
이 문제에 대하여, 여러개의 가상머신을 생성하는 것으로 이 문제를 해결하려고 노력
# 하이퍼바이저에 의한 서버 환경의 문제점 2
무수히 많은 가상 머신을 생성한 후, 동일한 어플리케이션의 서로 다른 버전 또는 단순히 복제된 동일 버전을 설치/구동
의존성의 문제를 해결하지 못해서, 불가피하게 수 많은 가상머신을 만들어낼 수 밖에 없었다는 것이 문제 비용이 많이 들고, 모든면에서 비 효과적이고, 하드웨어 측면에서 또한 비 효과적임 ⇒ 이 문제를 해결하기 위해 등장한 것이 Container
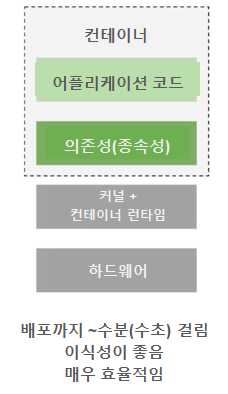
# 컨테이너에 의한 서버 환경
컨테이너 단위의 다른 수준의 추상화 방식 - 하드웨어 계층과의 분리 - {커널, 컨테이너 런타임} 계층과의 분리
즉, 위 두 가지 계층을 어떤 종류든지간에 어플리케이션과 어플리케이션에 필요한 의존성으로 부터 분리
매우 이식성이 좋고, 매우 효율적인 장점
# 컨테이너에 의한 서버 환경 - 개발자들에게 인기 있는 이유
어플리케이션은 어디에서든, 동일하게 동작 - 개발, 테스트, 프로덕션 어떤 환경에서든 - 베어메탈, 가상머신, 클라우드 어떤 환경에서든
패키지화된 어플리케이션은 개발 싸이클의 속도를 빠르게 회전시킴 - 애자일한 생성과 배포가 가능 - 지속적인 통합/배포가 가능 - 단일 파일의 복사만으로 이를 가능하게 해줌
마이크로서비스를 가능하게 해 주기 위한 방법을 제공: - 분석 가능성(introspectable), 격리성(isolated), 탄력성(elastic)
# 12년에 걸친 컨테이너의 역사
# 도커 오버뷰
도커 컨테이너와 이미지의 관계 - 이미지: 일종의 실행가능한 컨테이너를 생성하는데 사용되는 템플릿 - 컨테이너: 이미지 기반의 실제 실행가능한 이미지 인스턴스
왼쪽 그림과 같이, ubuntu 라는 생성된 이미지는건드릴 수 없는 Read Only 계층. 인스턴스를 찍어내기 위한 템플릿이라고 생각해 보면 당연한 내용 이미지라는 템플릿으로부터 여러개의동일한 컨테이너라고 불리는 인스턴스를 찍어낼 수 있음. ⇒ 인스턴스가 되었기 때문에, Read Write 가능한 계층
Google, Amazon 및 Microsoft와 같은 퍼블릭 클라우드 제공 업체는 컴퓨팅, 스토리지, 네트워킹 및 기타 인프라를 배치하여 광범위한 비즈니스 서비스 및 애플리케이션을 실행하기위한 다양한 서비스를 제공합니다. 퍼블릭 클라우드 제공 업체는 크게 네 가지 범주로 분류되는 서비스를 제공합니다.
Compute resources
Storage
Networking
Specialized services such as Machine Learning Services
클라우드 고객은 일반적으로 이러한 범주 중 하나 이상에서 서비스를 사용합니다.
컴퓨팅 리소스 Compute Resources
컴퓨팅 리소스는 퍼블릭 클라우드에서 다양한 형태로 제공됩니다.
가상 머신 Virtual Machines
가상 머신은 컴퓨팅 리소스의 기본 단위이며 클라우드 실험을 위한 좋은 출발점입니다. 클라우드 공급자로 계정을 만들고 청구 정보를 제공 한 후 포털 또는 명령 줄 도구를 사용하여 VM을 만들 수 있습니다.
Google Cloud Platform은 다양한 수의 vCPU 및 메모리 양으로 사전 구성된 다양한 VM을 제공합니다. 사전 구성된 오퍼링이 요구 사항을 충족하지 않는 경우 사용자 정의 구성을 작성할 수도 있습니다.
VM을 생성 한 후에는 로그인하여 원하는대로 관리 할 수 있습니다. VM에 대한 전체 액세스 권한이 있으므로 파일 시스템을 구성하고, 영구 저장소를 추가하고, 운영 체제를 패치하거나 추가 패키지를 설치할 수 있습니다.
VM에서 실행할 대상, 다른 사람에게 액세스 권한 및 VM 종료시기를 결정합니다. 관리하는 VM은 사무실에 전체 관리자 권한이있는 서버가있는 것과 같습니다.
물론 서로 다른 운영 체제 및 응용 프로그램을 실행하는 여러 VM을 만들 수 있습니다. 또한 GCP는 분산 백엔드에 단일 액세스 지점을 제공하는로드 밸런서와 같은 서비스를 제공합니다.
응용 프로그램에 고 가용성이 필요한 경우 특히 유용합니다. 클러스터의 VM 중 하나에 장애가 발생하면 작업 부하를 클러스터의 다른 VM으로 보낼 수 있습니다. 오토 스케일러는 워크로드를 기반으로 클러스터에서 VM을 추가하거나 제거 할 수 있습니다. 이를 자동 확장autoscaling이라고합니다.
이를 통해 필요한 것보다 많은 VM을 실행하지 않고도 비용을 제어하고 워크로드가 증가 할 때 충분한 컴퓨팅 용량을 사용할 수 있습니다.
Google Cloud Platform은 서버 클러스터를 생성하고 관리하는 데 필요한 모든 도구를 제공합니다.
많은 클라우드 사용자는 서버 클러스터를 유지하고 실행하는 데 필요한 작업이 아니라 자신의 애플리케이션에 집중합니다. 해당 사용자에게는 관리 클러스터가 좋은 옵션입니다.
관리 클러스터는 컨테이너를 사용합니다. 컨테이너는 하나의 컨테이너에서 실행중인 프로세스를 동일한 서버의 다른 컨테이너에서 실행중인 프로세스와 격리시키는 경량 VM과 같습니다.
관리 클러스터에서는 실행하려는 서버 수와 서버에서 실행할 컨테이너를 지정할 수 있습니다. 자동 확장 매개 변수autoscaling parameters를 지정하여 실행중인 컨테이너 수를 최적화 할 수도 있습니다.
관리 클러스터에서 컨테이너의 상태가 모니터링됩니다. 컨테이너가 실패하면 클러스터 관리 소프트웨어가 컨테이너를 감지하고 다른 컨테이너를 시작합니다.
컨테이너는 환경에서 실행중인 여러 마이크로 서비스에 의존하는 응용 프로그램을 실행해야 할 때 유용한 옵션입니다. 서비스는 컨테이너를 통해 배포되며 클러스터 관리 서비스는 모니터링, 네트워킹 및 일부 보안 관리 작업을 처리합니다.
서버리스 컴퓨팅 - Serverless Computing
VM과 관리되는 kubernetes 클러스터 모두 컴퓨팅 리소스를 구성하고 관리하기 위해 어느 정도의 노력이 필요합니다. 서버리스 컴퓨팅은 개발자와 응용 프로그램 관리자가 VM 또는 kubernetes 클러스터를 설정할 필요가없는 컴퓨팅 환경에서 코드를 실행할 수있는 접근 방식입니다.
Google Cloud Platform에는 두 가지 서버리스 컴퓨팅 옵션이 있습니다. 앱 엔진 및 클라우드 기능App Engine and Cloud Functions.. App Engine은 웹 사이트 백엔드, POS 시스템 또는 사용자 지정 비즈니스 응용 프로그램과 같이 오랫동안 실행되는 응용 프로그램 및 컨테이너에 사용됩니다.
Cloud Functions는 파일 업로드 또는 메시지 대기열에 메시지 추가와 같은 이벤트에 대한 응답으로 코드를 실행하기위한 플랫폼입니다. 이 서버리스 옵션은 함수로 코딩 된 짧은 프로세스를 실행하거나 VM, 관리 클러스터 또는 App Engine에서 실행될 수있는 장기 실행 애플리케이션을 호출하여 이벤트에 응답해야 할 때 효과적입니다.
저장소 Storage
퍼블릭 클라우드는 광범위한 애플리케이션 요구 사항에 유용한 몇 가지 유형의 스토리지 서비스를 제공합니다. 이러한 유형에는 다음이 포함됩니다.
■ 객체 저장 Object storage ■ 파일 저장 File storage ■ 블록 저장 Block storage ■ 캐시 Caches 클라우드 서비스의 엔터프라이즈 사용자는 종종 이러한 서비스의 조합을 사용합니다
객체 스토리지 Object Storage
오브젝트 스토리지는 오브젝트 또는 Blob 측면에서 스토리지 사용을 관리하는 시스템입니다. 일반적으로 이러한 객체는 파일이지만 기존 파일 시스템에 파일이 저장되어 있지 않다는 점에 유의해야합니다. 객체는 버킷으로 그룹화됩니다. 각 객체는 일반적으로 URL을 통해 개별적으로 주소를 지정할 수 있습니다.
오브젝트 스토리지는 서버에 연결된 디스크 또는 SSD (Solid-State Drive)의 크기에 의해 제한되지 않습니다. 디스크에서 사용 가능한 공간의 크기에 관계없이 객체를 업로드 할 수 있습니다. 가용성과 내구성을 향상시키기 위해 여러 개의 객체 사본이 저장됩니다. 경우에 따라 지역에 액세스 할 수없는 경우에도 가용성을 보장하기 위해 객체 사본이 다른 지역에 저장 될 수 있습니다.
객체 스토리지의 또 다른 장점은 서버리스serverless라는 것입니다. VM을 생성하고 스토리지를 연결할 필요가 없습니다. Cloud Storage라고하는 Google Cloud Platform의 객체 저장소는 GCP에서 실행되는 서버와 인터넷에 액세스 할 수있는 다른 장치에서 액세스 할 수 있습니다.
개체 수준에서 액세스 제어를 적용 할 수 있습니다. 이를 통해 클라우드 스토리지 사용자는 객체에 액세스하고 업데이트 할 수있는 사용자를 제어 할 수 있습니다.
파일 저장 File Storage
파일 스토리지 서비스는 파일을위한 계층 적 스토리지 시스템을 제공합니다. 파일 시스템 스토리지는 네트워크 공유 파일 시스템을 제공합니다. Google Cloud Platform에는 NFS (Network File System) 스토리지 시스템을 기반으로하는 Cloud Filestore라는 파일 스토리지 서비스가 있습니다.
파일 저장소는 파일에 대한 파일 액세스와 같은 운영 체제가 필요한 응용 프로그램에 적합합니다. 파일 스토리지 시스템은 파일 시스템을 특정 VM에서 분리합니다.
파일 시스템, 디렉토리 및 파일은 해당 파일에 액세스 할 수있는 VM 또는 응용 프로그램과 독립적으로 존재합니다.
블록 스토리지 Block Storage
블록 스토리지는 블록이라는 고정 크기 데이터 구조를 사용하여 데이터를 구성합니다. 블록 스토리지는 일반적으로 VM에 연결된 임시 및 영구 디스크에 사용됩니다. 블록 스토리지 시스템을 사용하면 블록 스토리지 위에 파일 시스템을 설치하거나 블록에 직접 액세스하는 애플리케이션을 실행할 수 있습니다.
일부 관계형 데이터베이스는 파일 시스템을 통해 작업하는 대신 블록에 직접 액세스하도록 설계 될 수 있습니다. Linux 파일 시스템에서 4KB는 일반적인 블록 크기입니다.
관계형 데이터베이스는 종종 블록에 직접 쓰지만 종종 8KB 이상과 같은 더 큰 크기를 사용합니다. 블록 스토리지는 Google Cloud Platform에서 VM에 연결된 디스크에서 사용할 수 있습니다.
블록 스토리지는 영구적이거나 임시 일 수 있습니다. 영구 디스크는 가상 서버 또는 디스크가 연결된 가상 서버에서 분리 된 경우에도 계속 존재하며 데이터를 저장합니다.
임시 디스크는 VM이 실행되는 동안에 만 존재하며 데이터를 저장합니다. 임시 디스크는 운영 체제 파일과 VM을 종료 할 때 삭제되는 기타 파일 및 데이터를 저장합니다.
영구 디스크는 데이터가 블록에 존재하기를 원할 때 사용됩니다 VM과 독립적 인 저장 장치. 이러한 디스크는 VM의 수명주기와 무관하게 사용 가능한 데이터가 있고 빠른 운영 체제 및 파일 시스템 수준 액세스를 지원할 때 유용한 옵션입니다.
객체 스토리지는 또한 데이터를 VM의 수명주기와 독립적으로 유지하지만 운영 체제 또는 파일 시스템 레벨 액세스는 지원하지 않습니다. 객체에 액세스하려면 HTTP와 같은 고급 프로토콜을 사용해야합니다. 블록 스토리지에서 데이터를 검색하는 것보다 오브젝트 스토리지에서 데이터를 검색하는 데 시간이 더 걸립니다.
애플리케이션 요구 사항을 충족시키기 위해 객체 스토리지와 블록 스토리지의 조합이 필요할 수 있습니다. 오브젝트 스토리지는 필요할 때 영구 디스크에 복사되는 대량의 데이터를 저장할 수 있습니다.
이 조합은 필요할 때 운영 체제 및 파일 시스템 기반 액세스와 함께 대용량 스토리지의 이점을 제공합니다.
캐시 Caches
캐시는 데이터에 빠르게 액세스하는 메모리 내 데이터 저장소입니다. 데이터를 검색하는 데 걸리는 시간을 대기 시간이라고합니다. 인 메모리 저장소의 대기 시간은 1 밀리 초 미만으로 설계되었습니다. 비교를 위해 다음과 같은 다른 대기 시간이 있습니다.
■ 주 메모리 참조를 만드는 데 100 나노초 또는 0.1 마이크로 초 ■ SSD에서 무작위로 4KB를 읽는 데 150 마이크로 초 소요 ■ 메모리에서 1MB를 순차적으로 읽는 데 250 마이크로 초 소요 ■ SSD에서 순차적으로 1MB를 읽으려면 1,000 마이크로 초 또는 1 밀리 초가 걸립니다. ■ 디스크에서 1MB를 순차적으로 읽는 데 20,000 마이크로 초 또는 20 밀리 초 소요
다음은 참조 용 변환입니다. ■ 1,000 나노초는 1 마이크로 초와 같습니다. ■ 1,000 마이크로 초는 1 밀리 초와 같습니다. ■ 1,000 밀리 초는 1 초입니다. 이들 및 기타 유용한 타이밍 데이터는 Jonas Bonér의 "모든 프로그래머가 알아야하는 지연 시간 번호"(https://gist.github.com/jboner/2841832) 확인할 수 있습니다.
1MB의 데이터를 읽는 예를 살펴 보겠습니다. 메모리 내 캐시에 데이터를 저장 한 경우 250 마이크로 초 또는 0.25 밀리 초로 데이터를 검색 할 수 있습니다. 동일한 데이터가 SSD에 저장된 경우 1 밀리 초에서 검색하는 데 4 배의 시간이 걸립니다.
하드 디스크 드라이브에서 동일한 데이터를 검색하는 경우 메모리 내 캐시에서 읽는 동안 20 밀리 초 또는 80 배 정도 기다릴 수 있습니다. 캐시는 애플리케이션에서 읽기 대기 시간을 최소로 유지해야 할 때 매우 유용합니다. 물론, 빠른 검색 시간을 좋아하지 않는 사람은 누구입니까? 데이터를 항상 캐시에 저장하지 않는 이유는 무엇입니까? 세 가지 이유가 있습니다.
■ 메모리는 SSD 또는 하드 디스크 드라이브 (HDD) 저장 장치보다 비쌉니다. 대부분의 경우 SSD 또는 HDD의 영구 블록 스토리지만큼 많은 인 메모리 스토리지를 보유하는 것은 실용적이지 않습니다. ■ 캐시는 일시적입니다. 전원이 꺼 지거나 운영 체제가 재부팅되면 캐시에 저장된 데이터가 손실됩니다. 빠른 액세스를 위해 캐시에 데이터를 저장할 수 있지만 데이터를 유지하는 유일한 데이터 저장소로 사용해서는 안됩니다. “진정한 시스템”또는 항상 최신의 가장 정확한 버전의 데이터를 보유한 데이터 저장소를 유지하기 위해 어떤 형태의 영구 저장소를 사용해야합니다. ■ 캐시는 실제 시스템과 동기화되지 않을 수 있습니다. 이는 진실 시스템이 업데이트되었지만 새 데이터가 캐시에 기록되지 않는 경우 발생할 수 있습니다. 이 경우 캐시에 의존하는 애플리케이션이 캐시의 데이터가 유효하지 않다는 사실을 감지하기 어려울 수 있습니다. 캐시를 사용하기로 결정한 경우 캐시와 시스템 사이의 일관성에 대한 요구 사항을 충족하는 캐시 업데이트 전략을 설계해야합니다.
네트워킹 Networking
클라우드에서 작업 할 때는 클라우드 리소스와 온-프레미스 시스템 간의 네트워킹 작업을 수행해야합니다. 클라우드 환경에서 여러 개의 VM을 실행중인 경우 어느 시점에서 IP 주소를 관리해야 할 수 있습니다. 사용자 환경의 각 네트워크 액세스 가능 장치 또는 서비스에는 IP 주소가 필요합니다. 실제로 GCP 내의 기기는 외부 주소. 내부 주소는 내부 GCP 네트워크의 서비스에만 액세스 할 수 있습니다.
내부 GCP 네트워크는 VPC (Virtual Private Cloud)로 정의됩니다. 인터넷에서 외부 주소에 액세스 할 수 있습니다. 외부 IP 주소는 고정 또는 임시 일 수 있습니다. 고정 주소는 오랫동안 장치에 할당됩니다.
임시 외부 IP 주소는 VM에 연결되고 VM이 중지되면 해제됩니다. IP 주소를 지정하는 것 외에도 VPC의 서브 네트워크 및 VM에 대한 액세스를 제어하기 위해 방화벽 규칙을 정의해야하는 경우가 종종 있습니다. 예를 들어, 응용 프로그램 서버 (AS)만이 데이터베이스를 조회 할 수 있도록 액세스를 제한하려는 데이터베이스 서버가있을 수 있습니다.
인바운드 및 아웃 바운드를 제한하도록 방화벽 규칙을 구성 할 수 있습니다. 애플리케이션 클러스터 앞의 애플리케이션 서버 또는로드 밸런서의 IP 주소로의 트래픽. 온 프레미스 데이터 센터와 VPC간에 데이터 및 네트워크 액세스를 공유해야 할 수도 있습니다.
여러 유형의 피어링 중 하나를 사용하여이 작업을 수행 할 수 있습니다. 이는 고유 한 네트워크를 연결하는 일반적인 용어입니다.
전문화 된 서비스 Specialized Services
대부분의 퍼블릭 클라우드 제공 업체는 애플리케이션 블록을 구축하거나 데이터 처리를위한 워크 플로의 일부로 사용할 수있는 전문화 된 서비스를 제공합니다. 전문 서비스의 일반적인 특징은 다음과 같습니다.
■ 서버리스입니다. 서버 나 클러스터를 구성 할 필요가 없습니다. ■ 텍스트 번역 또는 이미지 분석과 같은 특정 기능을 제공합니다. ■ 서비스 기능에 액세스하기위한 API (응용 프로그래밍 인터페이스)를 제공합니다. ■ 다른 클라우드 서비스와 마찬가지로 서비스 사용에 따라 요금이 부과됩니다.
다음은 Google Cloud Platform의 전문화 된 서비스 중 일부입니다. ■ 머신 러닝 서비스 인 AutoML ■ 텍스트 분석을위한 서비스 인 Cloud Natural Language ■ 이미지 분석을위한 클라우드 비전 ■ 시계열 데이터에 대한 상관 관계를 계산하기위한 서비스 인 Cloud Inference API.
전문화 된 서비스는 고급 컴퓨팅 기능을 캡슐화하여 자연 언어 처리 및 기계 학습과 같은 도메인의 전문가가 아닌 개발자가 액세스 할 수 있도록합니다. Google Cloud Platform에 더 전문화 된 서비스가 추가 될 것으로 예상됩니다.
Google 클라우드 플랫폼(GCP)는 Google의 인프라에서 호스팅 클라우드 서비스의 모음입니다.컴퓨팅 및 스토리지에서 데이터 분석, 머신 러닝 및 네트워킹에 이르기까지 GCP는 개인 또는 엔터프라이즈 급의 클라우드 컴퓨팅 애플리케이션 또는 프로젝트와 통합 할 수있는 다양한 서비스 및 API를 제공합니다.
이 입문 실습에서는Google Cloud 서비스에 액세스하고 관리 할 수있는 브라우저 내부 UI 인Google Cloud Platform 콘솔을사용하여 실습을 통해 GCP를 시작합니다.GCP의 주요 기능을 식별하고 Qwiklabs 환경의 기능을 익힐 것입니다.클라우드 컴퓨팅을 처음 사용하거나 GCP 및 Qwiklabs에 대한 개요를 찾고 있다면 올바른 위치에 있습니다.이 실습의 세부 사항과 실습 영역에 대해 자세히 알아보십시오.
무엇을 배울 것인가
이 실습에서는 다음을 수행합니다.
Qwiklabs 플랫폼에 대해 알아보고 실험실 환경의 주요 기능을 식별하십시오.
Qwiklabs 크레딧에 대해 배우고 구입하여 랩 인스턴스를 시작하십시오.
특정 자격 증명으로 GCP 콘솔에 액세스하는 방법에 대해 알아보십시오.
GCP 프로젝트에 대해 배우고이를 둘러싼 일반적인 오해를 식별하십시오.
GCP 탐색 메뉴를 사용하여 GCP 서비스 유형을 식별하는 방법에 대해 알아 봅니다.
기본 역할에 대해 학습하고 Cloud IAM 서비스를 사용하여 특정 사용자가 사용할 수있는 조치를 검사하십시오.
Cloud Shell에 대해 학습하고gcloud툴킷을 사용하는 명령을 실행하십시오.
API 라이브러리에 대해 배우고 주요 기능을 조사하십시오.
클라우드 셸에서 미리 설치와 같은 명령을 실행할 수있는 툴을 사용touch,nano및cat파일의 내용을 생성, 편집, 출력 할 수 있습니다.
전제 조건
이실습은실습수준의실습실이며 GCP 또는 Qwiklabs에 익숙하지 않은 경우 가장 먼저 수행해야 할 실습실입니다.Qwiklabs 및 Google Cloud Platform 콘솔에 이미 경험이있는 경우 다음 실습을 확인하십시오 (실습하기로 결정한 경우지금 실습을종료하십시오).
주제 또는 전문 지식 수준에 관계없이 모든 Qwiklabs는 공통 인터페이스를 공유합니다.이 실습은 다음과 매우 유사합니다.
참고: 위에 표시된 "가상 머신 생성"랩을 사용하지 않고 Qwiklabs에서 공통 기능을 강조하기위한 예제로만 사용됩니다.
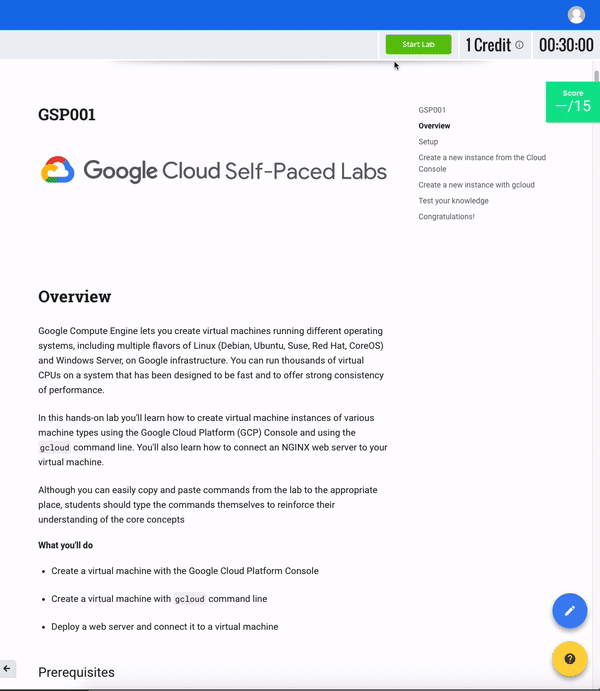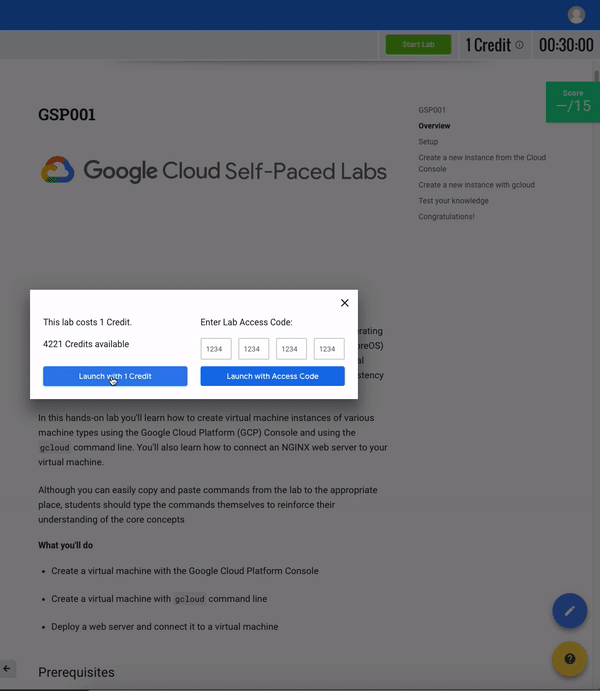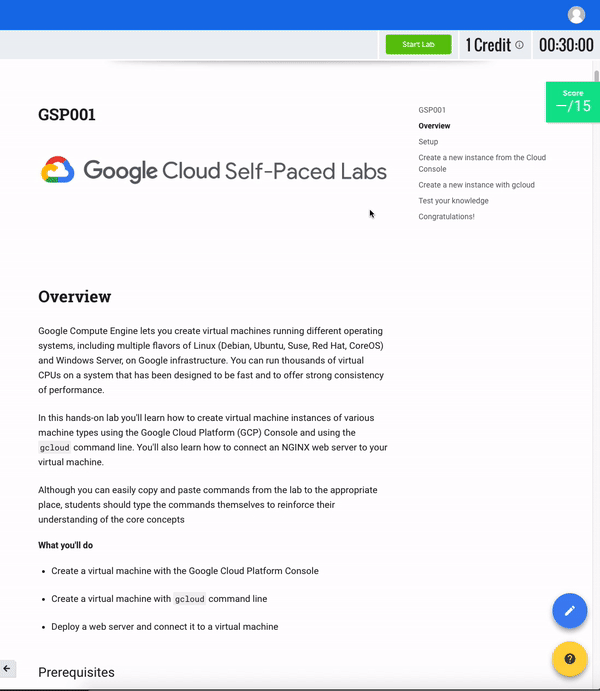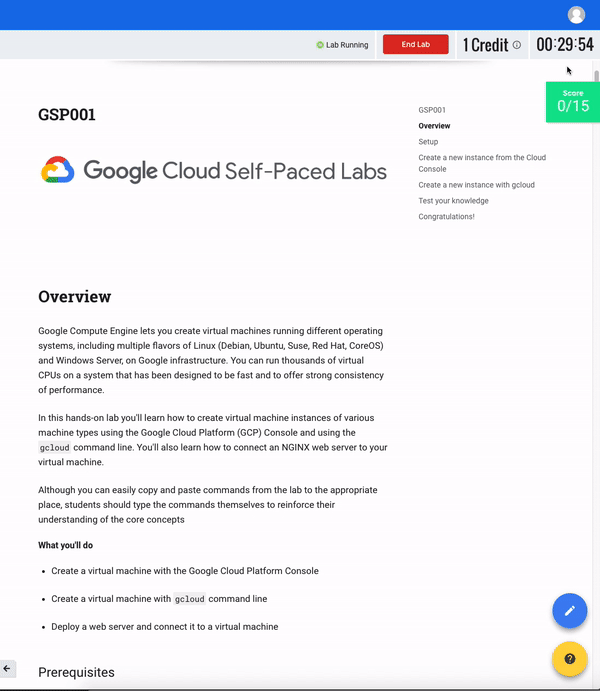
다음 실습 구성 요소 정의를 읽고 인터페이스의 오른쪽 상단에서 찾으십시오.
실습 시작 (버튼)
이를 클릭하면 필요한 모든 서비스와 자격 증명이 활성화 된 임시 GCP 환경이 만들어 지므로 실험실 자료를 통해 실습을 시작할 수 있습니다.클릭하면 실험실 단계를 완료하는 데 필요한 시간을 제공하는 카운트 다운 타이머가 시작됩니다.타이머가에 도달하면00:00:00랩 환경과 임시 자격 증명이 삭제됩니다.
신용
실험실 가격.1 학점은일반적으로 1 미국 달러 (구입 한 학점이 많을수록 더 많은 할인 혜택을받습니다)와 동일합니다. 기초 실습실 (이와 같은)은 1 학점, 기본 수준 5, 고급 7, 전문가 비용 9 학점입니다.보다 전문화 된 실험실은 더 많은 컴퓨팅 작업이 필요하고 더 많은 GCP 리소스를 요구하기 때문에 비용이 더 많이 듭니다.
시각
실습을 완료해야하는 시간을 지정합니다.앞에서 언급했듯이 "실험실 시작"버튼을 클릭하면 타이머가에 도달 할 때까지 카운트 다운됩니다00:00:00.그렇게되면 임시 GCP 환경과 리소스가 삭제됩니다.랩을 완료하는 데 충분한 시간이 주어 지지만 랩이 실행되는 동안 다른 작업을 수행하지 않도록하십시오. 모든 노력을 잃을 위험이 있습니다!
점수
대부분의 랩은 아니지만 점수가 포함되어 있습니다.이 기능을 "활동 추적"이라고하며 실험실에서 지정된 단계를 완료 할 수 있습니다.활동 추적 기능이있는 랩을 통과하려면 모든 단계를 순서대로완료해야합니다(그러면 완료 학점을 받게됩니다).
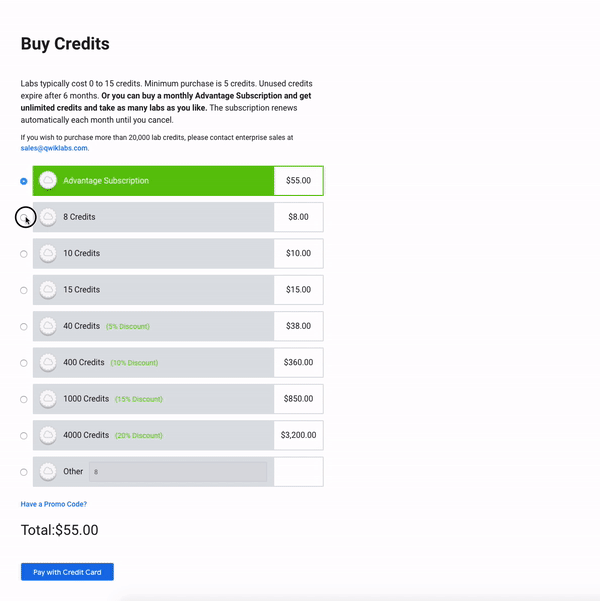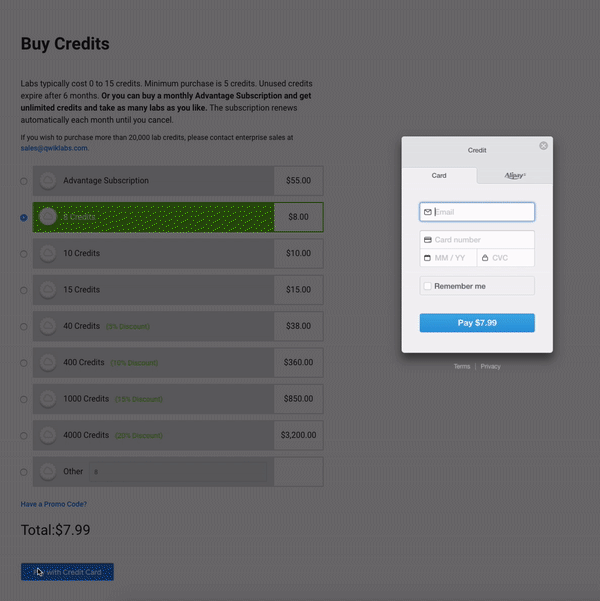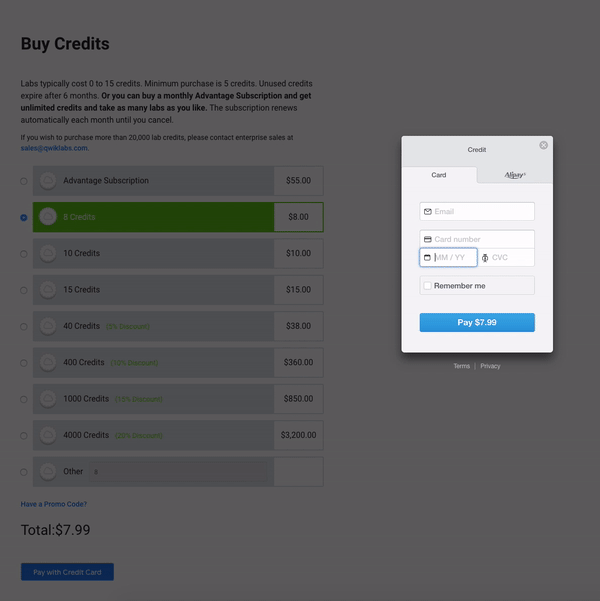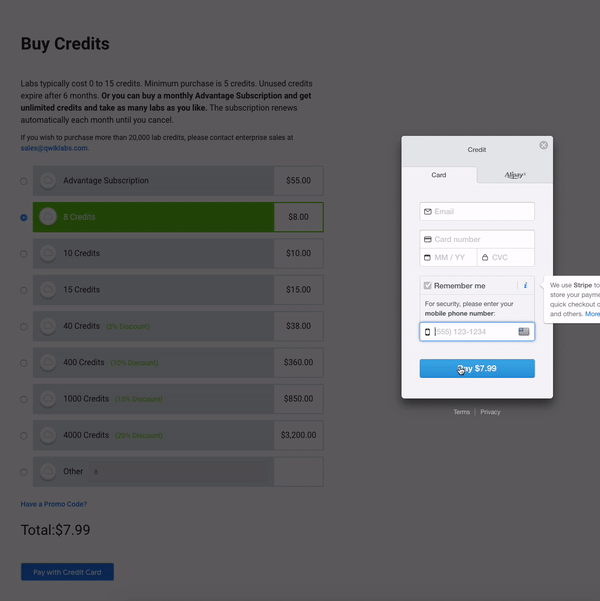
구매 크레딧
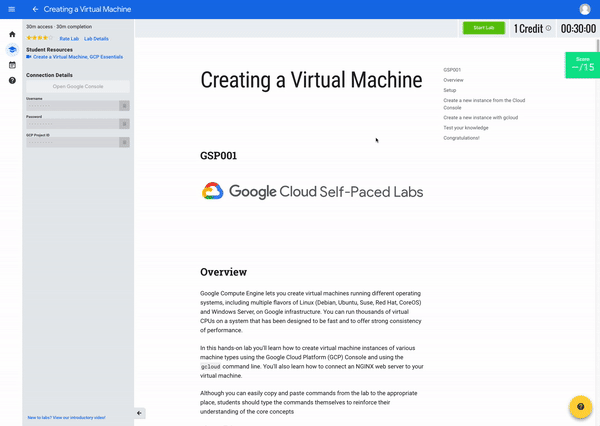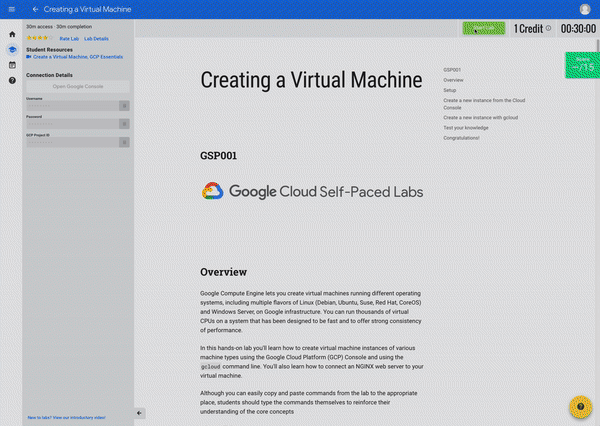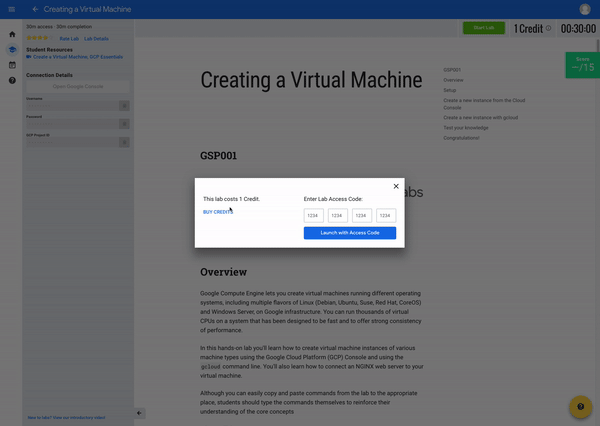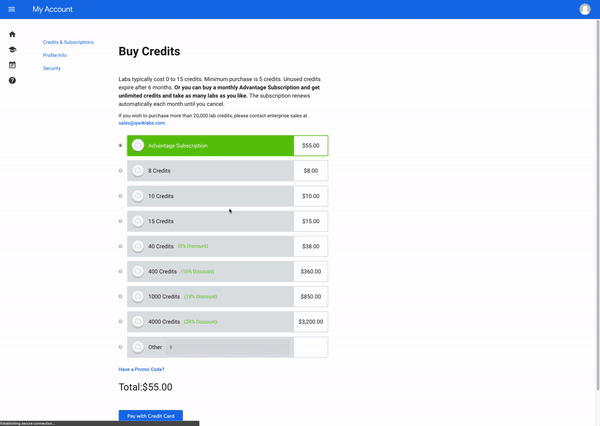
아직시작하지 않았다면지금실습 시작버튼을클릭하십시오."액세스 코드"(전문가 수준에 관계없이 단일 랩 비용을 충당하는 쿠폰)가 있거나 이미 크레딧을 구매 한 경우 다음 섹션 "랩 시작"으로 건너 뛸 수 있습니다.그렇지 않으면신용장 구입을클릭하십시오.다른 신용 패키지를 제공하는 새 페이지로 이동합니다.
구매하려는 크레딧 금액을 입력하고 신용 카드로 지불을클릭하십시오.그러면 신용 카드 정보를 입력하라는 보안 패널이 나타납니다.
신용 카드 정보를 입력하고지불을클릭하십시오.당신은 이것과 다른 Qwiklabs를 가져갈 준비가되었습니다!오른쪽 상단에있는 프로필 아이콘을 클릭하고 '크레딧 구매'를 선택하면 언제든지 더 많은 크레딧을 구매할 수 있습니다.또한 실습을 시작하고 새로운 실습을 시작하려고하면 추가 구매 메시지가 표시됩니다.
랩 시작
실습의 주요 기능과 구성 요소를 이해 했으므로오른쪽 상단 모서리에있는실습 시작버튼을클릭하십시오.액세스 코드가있는 경우 지금 입력하고 액세스 코드로 실행을클릭하십시오.그렇지 않으면1 크레딧으로 실행을클릭하십시오.
GCP 환경과 자격 증명이 표시 되려면 다소 시간이 걸릴 수 있습니다. 잠시만 기다려주세요.오른쪽 상단의 타이머가 작동하기시작하고 실습 시작버튼이실습 종료버튼으로 바뀌면모든 것이 제자리에 있으며 모두 Google Cloud Platform 콘솔에 로그인하도록 설정되었습니다.
필요한 모든 작업을 완료 할 때까지실험실 종료버튼을클릭하지 마십시오.클릭하면 임시 자격 증명이 무효화되어 실험실 전체에서 수행 한 작업에 더 이상 액세스 할 수 없습니다.끝 부분에 도달하고 필요한 모든 단계를 완료 한 경우에만실험실 종료단추를클릭하십시오.완료하면이 버튼을 클릭해야합니다. 그렇지 않으면 나중에 다른 실습을 수행 할 수 없습니다 (Qwiklabs는 동시 등록을 방지하는 보호 기능을 갖추고 있습니다).
GCP 콘솔에 액세스
핵심 용어
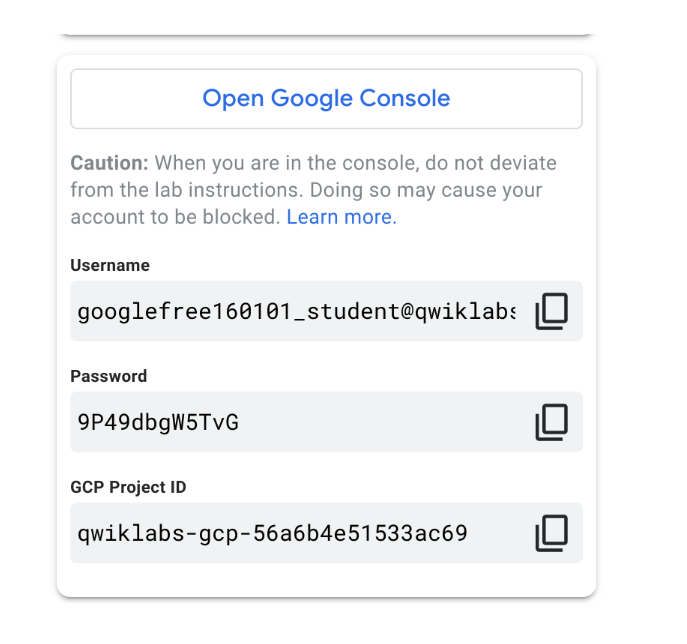
랩 인스턴스가 시작되어 왼쪽에있는 Connection Details (연결 세부 정보) 패널을 살펴보십시오.Google 콘솔 열기 버튼과 사용자 이름, 비밀번호 및 GCP 프로젝트 ID 필드로 채워 져야합니다.
참고: 자격 증명은 비슷하지만 위와 일치하지 않습니다. 랩 인스턴스마다 새로운 임시 자격 증명이 생성됩니다.
더 진행하기 전에 이러한 각 구성 요소를 살펴 보겠습니다.
Google 콘솔을 엽니 다
웹 콘솔 및 GCP의 중앙 개발 허브 인Google Cloud Platform 콘솔로 이동하는 버튼입니다.GCP에서 작업을 시작하면이 인터페이스에서 대부분의 작업을 수행하게됩니다.모든 GCP Qwiklabs는 어떤 형태로든 콘솔을 사용합니다.
GCP 프로젝트 ID
GCP 프로젝트는귀하의 Google 클라우드 자원에 대한 조직 엔티티입니다.여기에는 종종 리소스와 서비스가 포함됩니다. 예를 들어 가상 머신 풀, 데이터베이스 세트 및 서로 연결되는 네트워크가있을 수 있습니다.프로젝트에는 보안 규칙과 누가 어떤 리소스에 액세스 할 수 있는지를 지정하는 설정 및 권한도 포함됩니다.
GCP 프로젝트 ID는특정 프로젝트에 GCP 자원 및 API를 연결하는 데 사용되는 고유 식별자입니다.프로젝트 ID는 GCP에서 고유하므로 하나의qwiklabs-gcp-xxx ....만있을 수 있으므로전 세계적으로 식별 할 수 있습니다.
사용자 이름과 비밀번호
GCP 자격 증명 및 액세스 관리 (IAM) 서비스에서 액세스 권한 (역할 또는 역할)이있는 자격 증명으로, 할당 된 프로젝트에서 GCP 리소스를 사용할 수 있습니다.이 자격 증명은일시적이며 랩 액세스 시간 동안 만 작동합니다.즉, 타이머가 0에 도달하면 해당 자격 증명으로 더 이상 GCP 프로젝트에 액세스 할 수 없습니다.
GCP에 로그인
Connection Details (연결 세부 정보) 패널을 더 잘 이해 했으므로 이제 포함 된 세부 정보를 사용하여 GCP 콘솔에 로그인하겠습니다.Google 콘솔 열기버튼을클릭하십시오.새 브라우저 탭에서 GCP 로그인 페이지가 열립니다.
이제 다음과 유사한 페이지에 있어야합니다.
Gmail과 같은 Google 애플리케이션에 로그인 한 경우이 페이지가 익숙해 보일 것입니다.콘솔에 로그인하려면연결 세부 사항에서사용자 이름을복사하여 "이메일 또는 전화"필드에 붙여넣고 Enter 키를 누르십시오.
기다림!개인 또는 회사 이메일 주소가 아닌 googlexxxxxx_student@qwiklabs.net 이메일을 사용하여 로그인했는지 확인하십시오!
Qwiklabs 랩 페이지의 프로비저닝 된 자격 증명에서비밀번호를복사하여"비밀번호"필드의 GCP 사인에 붙여넣고 Enter 키를 누릅니다.
googlexxxxxx_student@qwiklabs.net과 유사한 사용자 이름은 Qwiklabs 학생으로 사용하기 위해 생성 된 Google 계정입니다.특정 도메인 이름 ( "qwiklabs.net")이 있으며 프로비저닝 된 GCP 프로젝트에 액세스 할 수있는 IAM 역할이 할당되었습니다.
로그인에 성공하면 페이지는 다음과 유사합니다.
계속해서동의를클릭하면 Google 서비스 약관 및 개인 정보 취급 방침에 대한 귀하의 인정을 나타냅니다.그러면 "계정 보호"페이지가 나타납니다.이 계정은 임시 계정이므로 복구 전화 번호 또는 이메일 업데이트에 대해 걱정하지 마십시오.완료를클릭하십시오.
이제 "서비스 약관 업데이트"페이지로 이동합니다. 향후 공지에 관한 이메일 업데이트는아니오상자를 선택하십시오.Google Cloud Platform의 서비스 약관에 동의하려면예확인란을 선택합니다.
Qwiklabs 자격 증명을 사용하여 Google Cloud Platform 콘솔에 성공적으로 액세스했습니다!이제 페이지가 다음과 유사해야합니다.
GCP 콘솔의 프로젝트
연결 세부 사항 패널의 구성 요소를 조사 할 때 앞서 GCP 프로젝트에 대해 살펴 보았습니다.다시 한 번 정의는 다음과 같습니다.
GCP 프로젝트는귀하의 Google 클라우드 자원에 대한 조직 엔티티입니다.여기에는 종종 리소스와 서비스가 포함됩니다. 예를 들어 가상 머신 풀, 데이터베이스 세트 및 서로 연결되는 네트워크가있을 수 있습니다.프로젝트에는 보안 규칙과 누가 어떤 리소스에 액세스 할 수 있는지를 지정하는 설정 및 권한도 포함됩니다.
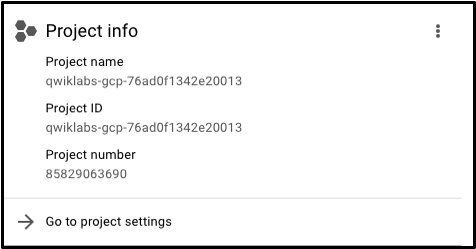
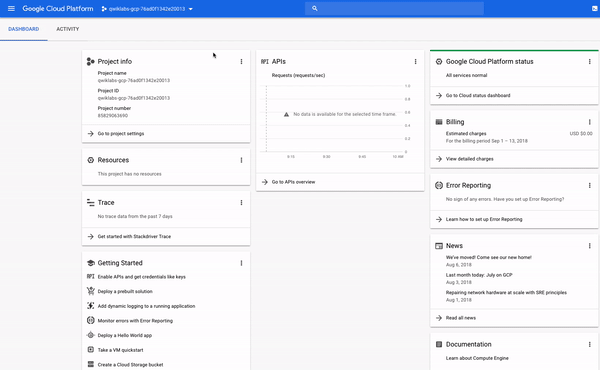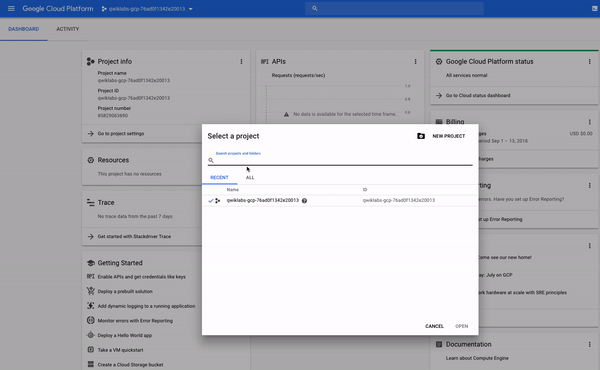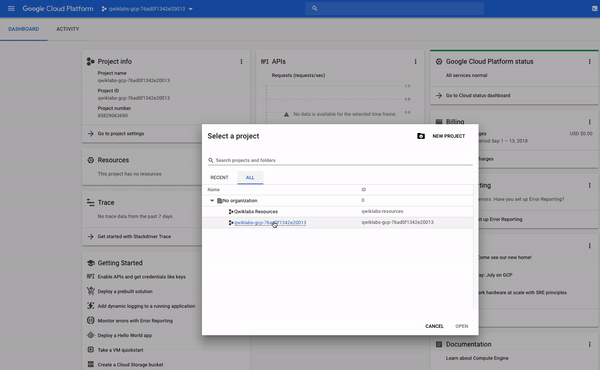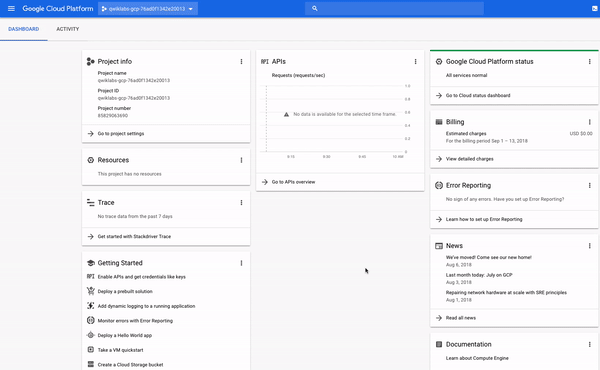
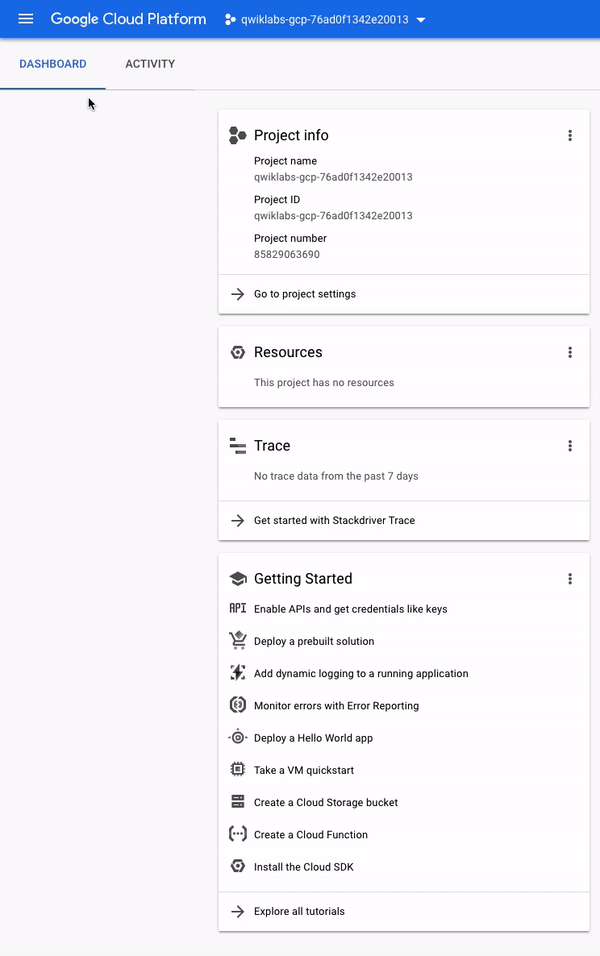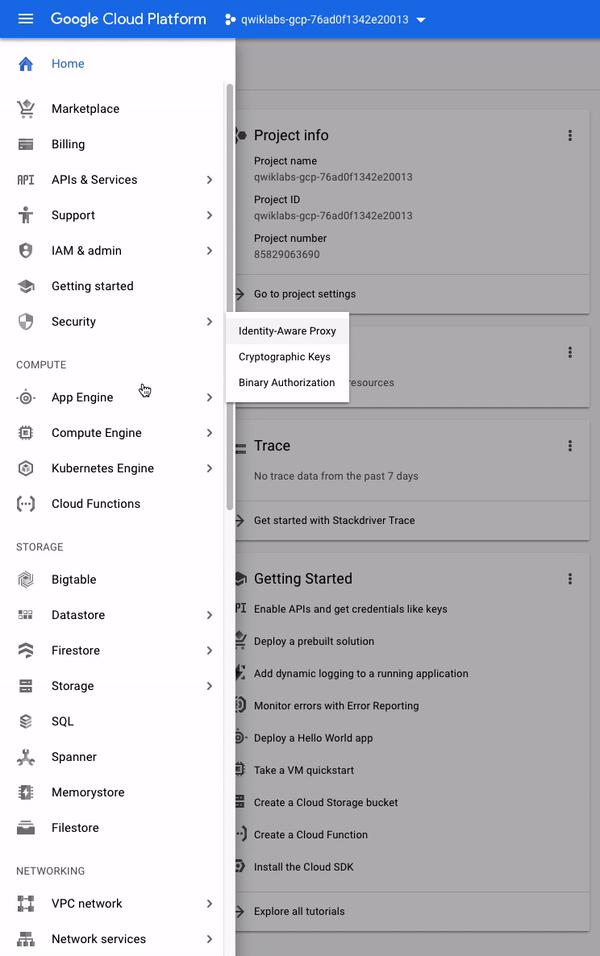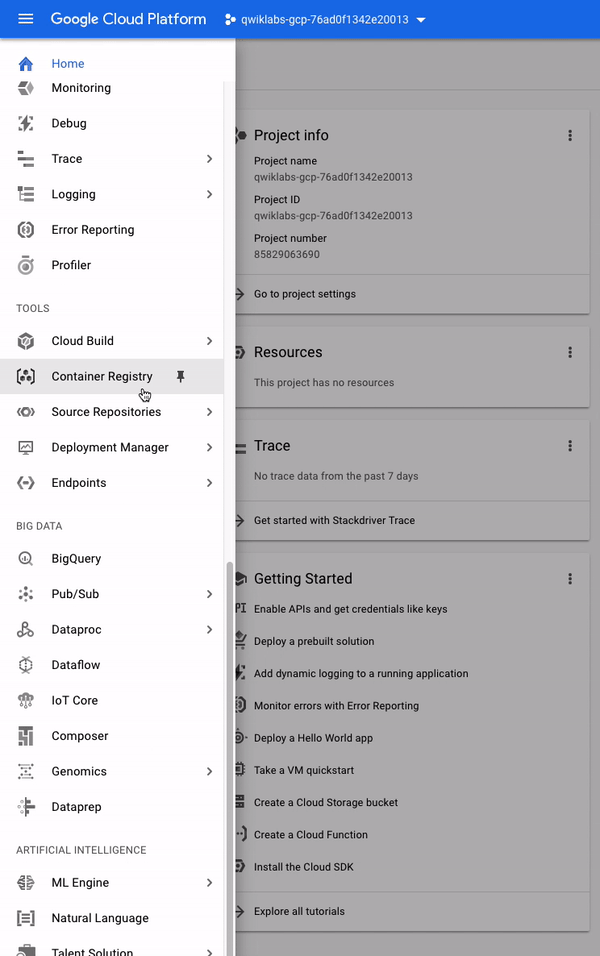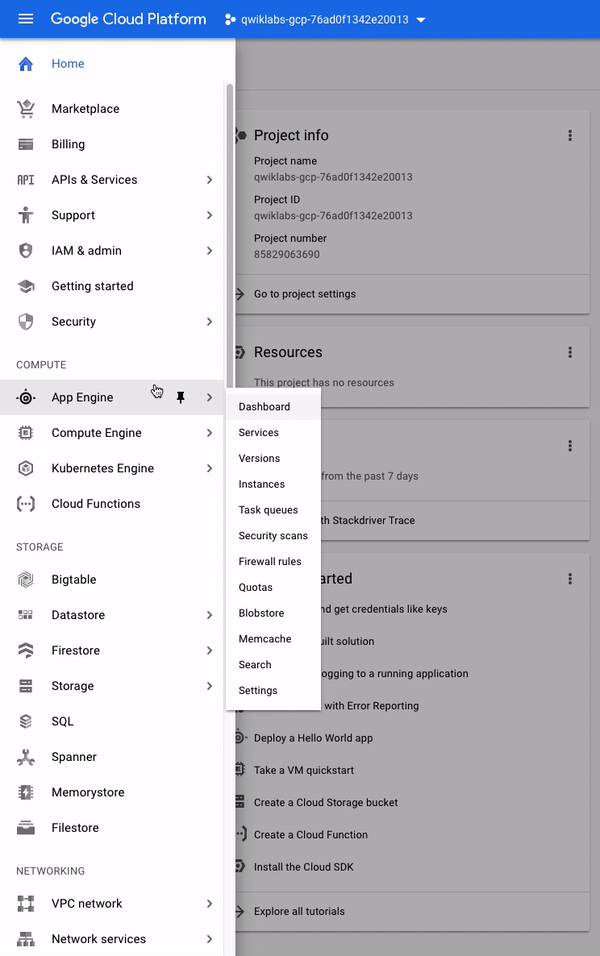
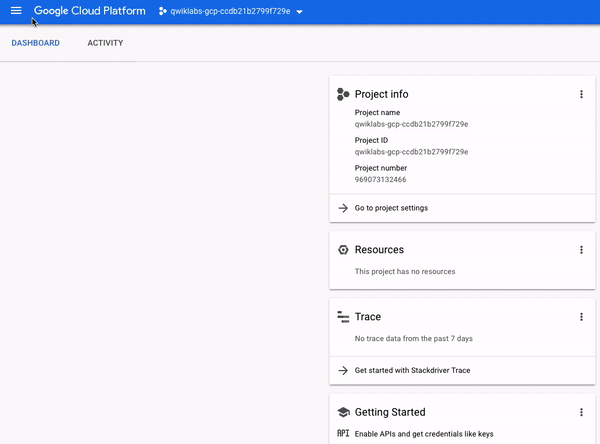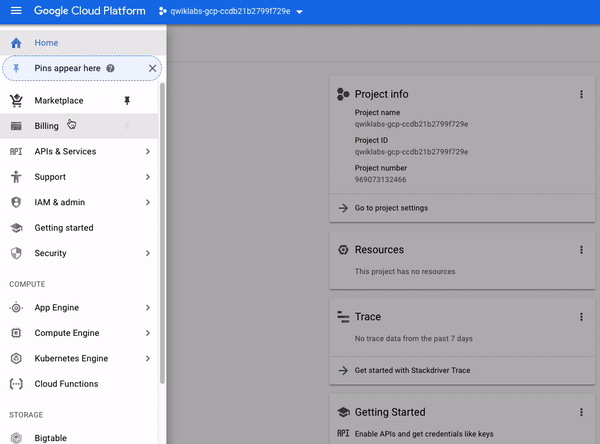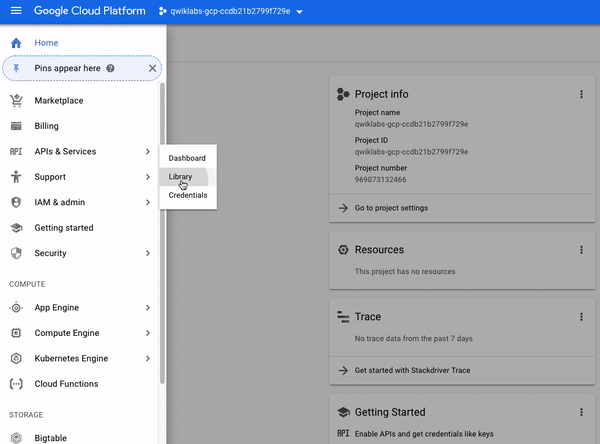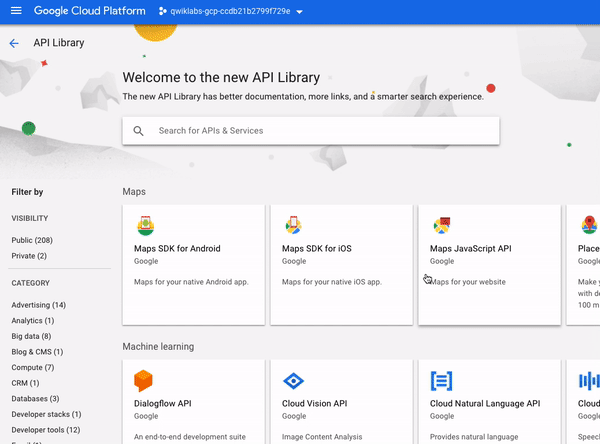
콘솔의 왼쪽 상단을 보면프로젝트 정보라는 패널이 표시되며 다음과 유사합니다.
보시다시피 프로젝트에는이름,ID및번호가있습니다.이러한 식별자는 GCP 서비스와 상호 작용할 때 자주 사용됩니다.GCP의 특정 서비스 또는 기능을 실습 할 수 있도록 하나의 프로젝트에서 작업하고 있습니다.
아마 눈치 채지 못했지만 실제로 둘 이상의 GCP 프로젝트에 액세스 할 수 있습니다.실제로 일부 랩에서는 할당 된 작업을 수행하기 위해 둘 이상의 프로젝트가 제공 될 수 있습니다.프로젝트 이름으로 드롭 다운 메뉴를 클릭하고ALL을선택하면 "Qwiklabs Resources"프로젝트도 볼 수 있습니다.
이 시점에서 Qwiklabs 리소스 프로젝트로 전환하지 마십시오!그러나 나중에 다른 실습에서 사용할 수 있습니다.
대기업이나 숙련 된 GCP 사용자가 수십에서 수천 개의 GCP 프로젝트를하는 것은 드문 일이 아닙니다.조직은 다른 방식으로 GCP를 사용하므로 프로젝트는 클라우드 컴퓨팅 서비스 (예 : 팀 또는 제품별로)를 분리하는 좋은 방법입니다.
"Qwiklabs Resources"는 특정 랩에 대한 파일, 데이터 세트 및 머신 이미지를 포함하는 프로젝트이며 모든 GCP 랩 환경에서 액세스 할 수 있습니다."Qwiklabs 리소스"는 모든 Qwiklabs 사용자와 공유 (읽기 전용)되므로 삭제하거나 수정할 수 없습니다.
실습 중이고이름이 비슷한 GCP 프로젝트qwiklabs-gcp-xxx...는일시적입니다. 즉, 실습이 종료되면 프로젝트 및 프로젝트에 포함 된 모든 항목이 삭제됩니다.새로운 실습을 시작할 때마다 하나 이상의 새로운 GCP 프로젝트에 액세스 할 수 있으며 모든 실습 단계를 실행할 수있는 곳 ( "Qwiklabs 리소스"가 아님)이 있습니다
탐색 메뉴 및 서비스
왼쪽 상단에 다음과 유사한 3 줄 아이콘이 있습니다.
이를 클릭하면GCP의 핵심 서비스를 가리키는탐색 메뉴가 표시되거나 숨겨집니다.메뉴가 표시되지 않으면 지금 아이콘을 클릭하고 스크롤하여 제공되는 서비스 유형을 확인하십시오.
탐색 메뉴는 GCP 콘솔의 중요한 구성 요소이며, 플랫폼 서비스에 빠르게 액세스 할 수 있으며 제품의 개요도 제공합니다.메뉴를 스크롤하면 7 가지 범주의 GCP 서비스가 있음을 알 수 있습니다.
컴퓨팅: 모든 유형의 워크로드를 지원하는 다양한 머신 유형을 수용합니다.다양한 컴퓨팅 옵션을 사용하면 무엇보다도 운영 세부 사항 및 인프라와의 관계를 결정할 수 있습니다.
스토리지: 구조적 또는 비 구조적, 관계형 또는 비 관계형 데이터를위한 데이터 스토리지 및 데이터베이스 옵션.
네트워킹: 애플리케이션 트래픽의 균형을 유지하고 보안 규칙을 제공하는 서비스입니다.
Stackdriver: 크로스 클라우드 로깅, 모니터링, 추적 및 기타 서비스 안정성 도구 모음입니다.
도구: 배포 및 응용 프로그램 빌드 파이프 라인을 관리하는 개발자를위한 서비스입니다.
빅 데이터: 대규모 데이터 세트를 처리하고 분석 할 수있는 서비스입니다.
인공 지능: Google Cloud 플랫폼에서 특정 인공 지능 및 기계 학습 작업을 실행하는 API 제품군입니다.
앞서 우리는 클라우드 컴퓨팅 서비스 외에도 누가 어떤 리소스에 액세스 할 수 있는지를 정의하는 권한 및 역할 모음도 포함하고 있다고 언급했습니다.우리는 사용할 수있는클라우드 ID 및 액세스 관리 (IAM)검사와 같은 역할 및 권한을 수정하는 서비스.
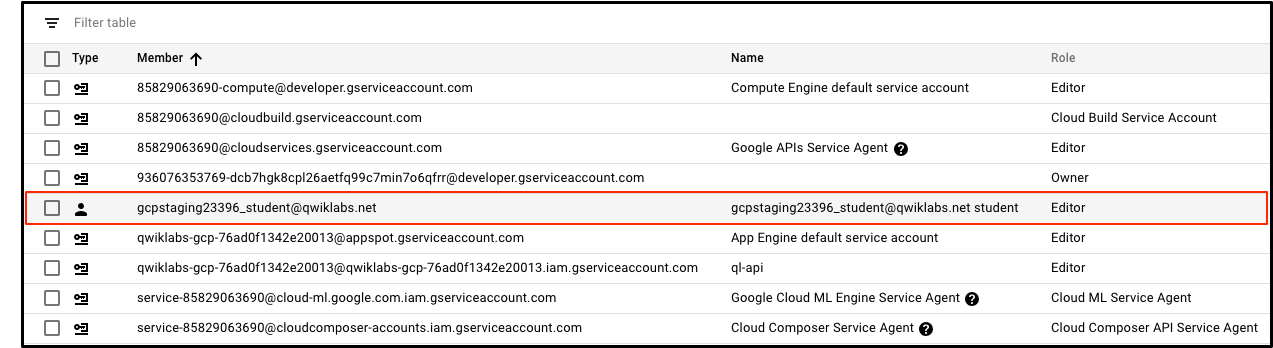
닫혀 있으면 탐색 메뉴를 엽니 다.그런 다음 상단 근처에서IAM & admin을클릭하십시오.특정 계정에 부여 된 권한 및 역할을 지정하는 사용자 목록이 포함 된 페이지로 이동합니다.이것들을 살펴보고 로그인 한 "@qwiklabs"사용자 이름을 찾으십시오.
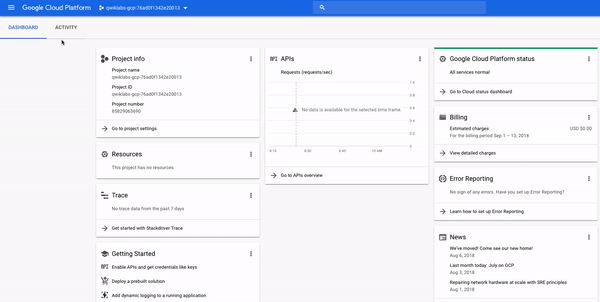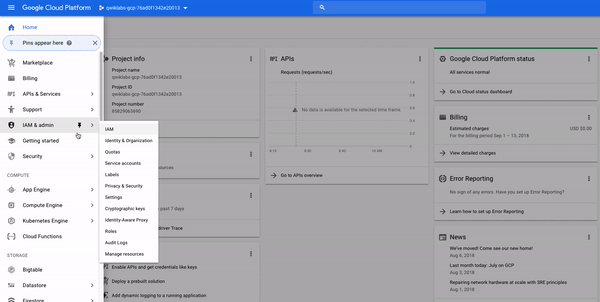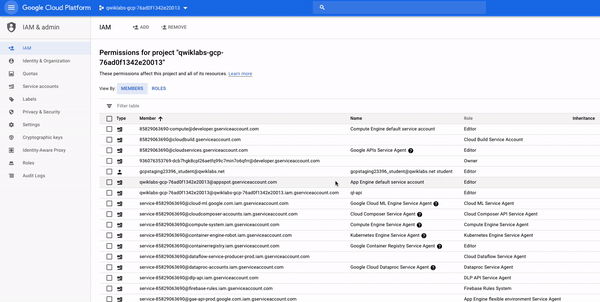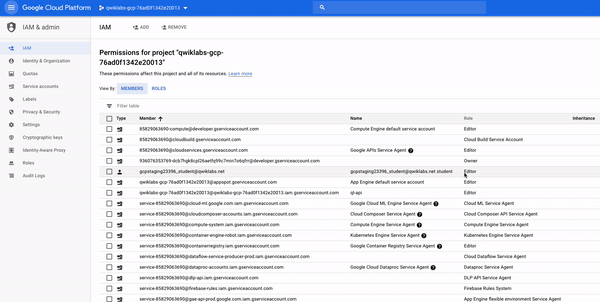
비슷한 것을 찾아야합니다.
멤버필드와 (당신이에 로그인 한 사용자 이름과 일치) "google23396_student@qwiklabs.net"로 설정되어이름필드가 "google23396_student@qwiklabs.net 학생"로 설정됩니다.역할필드가GCP에서 제공하는3 가지기본 역할중 하나 인 "편집기"로 설정되어있음을 알 수있습니다.기본 역할은 프로젝트 수준 권한을 설정하며 달리 지정하지 않는 한 모든 GCP 서비스에 대한 액세스 및 관리를 제어합니다.
다음 표는역할 문서에서 정의를 가져와뷰어, 편집기 및 소유자 역할 권한에 대한 간략한 개요를 제공합니다.
역할 이름
권한
역할 / 시청자
기존 리소스 또는 데이터보기 (수정은 안 됨)와 같이 상태에 영향을 미치지 않는 읽기 전용 작업에 대한 권한
역할 / 편집자
모든 뷰어 권한과 기존 리소스 변경과 같이 상태를 수정하는 작업에 대한 권한
역할 / 소유자
다음 작업에 대한 모든 편집자 권한 및 권한 :
프로젝트 및 프로젝트 내의 모든 리소스에 대한 역할 및 권한을 관리합니다.
프로젝트에 대금 청구를 설정하십시오.
따라서 편집자로서 GCP 리소스를 생성, 수정 및 삭제할 수 있습니다.그러나 GCP 프로젝트에서 회원을 추가하거나 삭제할 수 없습니다.
API 및 서비스
Google Cloud API는 Google Cloud Platform의 핵심 부분입니다.서비스와 마찬가지로 비즈니스 관리에서 기계 학습에 이르기까지 200 개 이상의 API는 모두 GCP 프로젝트 및 애플리케이션과 쉽게 통합됩니다.
API는 직접 또는 클라이언트 라이브러리를 통해 호출 할 수있는 "응용 프로그래밍 인터페이스"입니다.클라우드 API는Google API 디자인 가이드에설명 된대로 리소스 지향 디자인 원칙을 사용합니다.
Qwiklabs는 랩 인스턴스에 대해 새로운 GCP 프로젝트를 프로비저닝 할 때 대부분의 API를 백그라운드에서 지원하므로 랩의 작업을 바로 수행 할 수 있습니다.Qwiklabs 외부에서 자체 GCP 프로젝트를 생성 할 때는 특정 API를 직접 활성화해야합니다.
대부분의 Cloud API는 트래픽 수준, 오류율 및 지연 시간을 포함하여 프로젝트의 API 사용에 대한 자세한 정보를 제공하므로 Google 서비스를 사용하는 애플리케이션의 문제를 신속하게 심사 할 수 있습니다.탐색 메뉴를 열고API 및 서비스>라이브러리를클릭하여이 정보를 볼 수 있습니다.
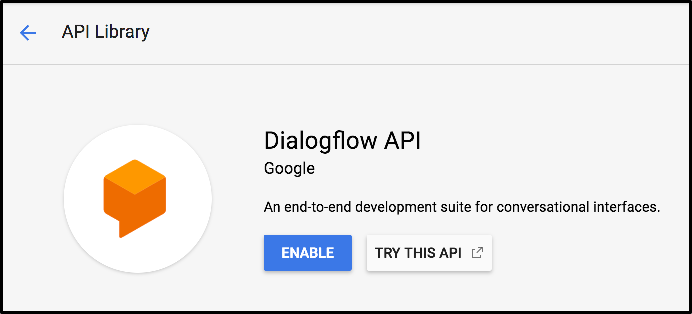
"CATEGORY"헤더가있는 왼쪽 메뉴를 보면 제공되는 모든 범주 유형이 표시됩니다.API 검색 표시 줄에서 Dialogflow를 입력하고Dialogflow API를선택하십시오.이제 다음 페이지에 있어야합니다.
Dialogflow API를 사용하면 기본 기계 학습 및 자연어 이해 스키마에 대해 걱정할 필요없이 풍부한 대화 형 응용 프로그램 (예 : Google Assistant)을 구축 할 수 있습니다.
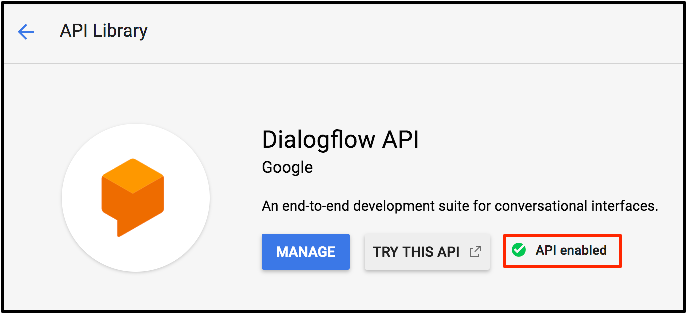
이제사용을클릭하십시오.새 페이지로 이동하고 브라우저에서 뒤로 버튼을 누르면 API가 활성화 된 것을 확인할 수 있습니다.
이제이API 사용해보기를클릭하십시오.그러면 새 대화 상자가 열리고 Dialogflow API 설명서가 표시되고 사용 가능한 방법이 지정됩니다.이 중 일부를 검사하고 완료되면 탭을 닫으십시오.
이제 GCP 및 콘솔의 주요 기능을 이해 했으므로Cloud Shell을통해 실습을 수행 할 수있습니다.Cloud Shell은 터미널 프롬프트에서 명령을 입력하여 GCP 프로젝트의 리소스 및 서비스를 관리 할 수있는 브라우저 내 명령 프롬프트 실행 환경입니다.
Cloud Shell을 사용하면 콘솔을 떠나지 않고도 모든 셸 명령을 실행할 수 있으며 사전 설치된 명령 줄 도구와 함께 제공됩니다.
콘솔의 오른쪽 상단에서Cloud Shell 활성화버튼을 클릭 한 후프롬프트가 표시되면Cloud Shell 시작을 클릭하십시오.
콘솔 하단에 다음과 유사한 메시지 및 프롬프트가 표시된 새로운 검은 창이 나타납니다.
Welcome to Cloud Shell! Type "help" to get started.
Your Cloud Platform project in this session is set to qwiklabs-gcp-76ad0f1342e20013.
Use "gcloud config set project [PROJECT_ID]" to change to a different project.
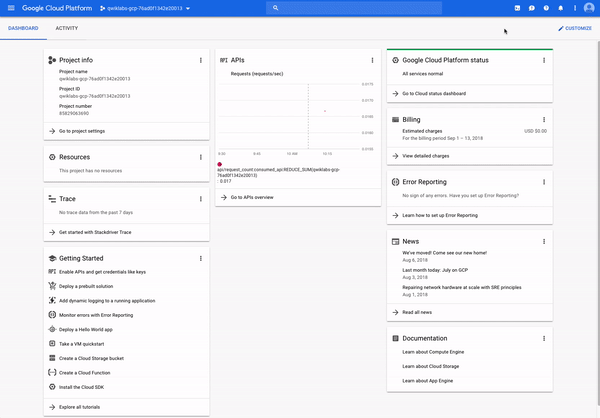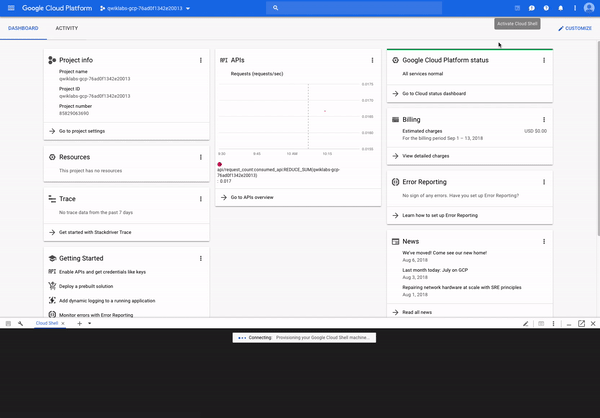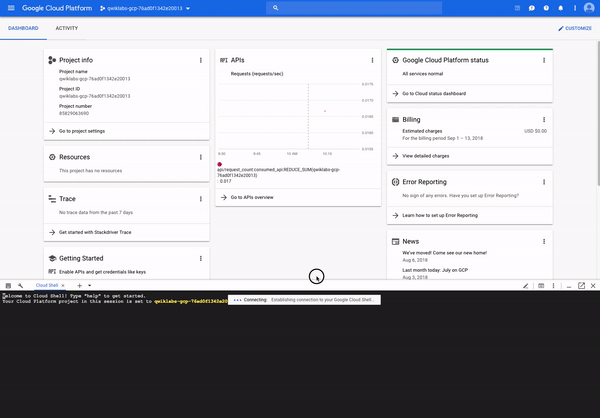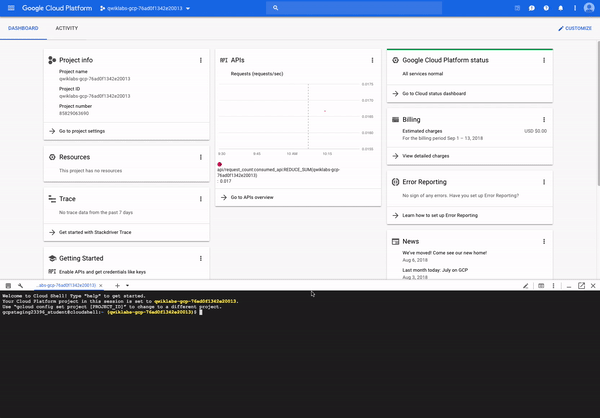
gcpstaging23396_student@cloudshell:~ (qwiklabs-gcp-76ad0f1342e20013)$
이제 Cloud Shell 세션이 시작되어 실행 중입니다.Cloud Shell에 다음을 복사하여 붙여 넣거나 입력하고 Enter 키를 누릅니다.
gcloud auth list
ACTIVE ACCOUNTGCP IAM 자격 증명 (gcpstagingxxxxx_student@qwiklabs.net)으로설정된유사한 출력이 표시되어야합니다.
Credentialed Accounts ACTIVE ACCOUNT * gcpstaging23396_student@qwiklabs.net
To set the active account,
run: $ gcloud config set account `ACCOUNT`
앞에서 언급했듯이 Cloud Shell에는 특정 명령 줄 도구가 사전 설치되어 있습니다.기본 GCP 툴킷은리소스 관리 및 사용자 인증과 같은 플랫폼의 많은 작업에 사용되는gcloud입니다.
인증 된 계정을 GCP 프로젝트에 나열하는gcloud명령 (auth list)을실행했습니다.이 계정 이름은 이전에 콘솔에 로그인 한 Qwiklabs 사용자 이름과 일치합니다.
Cloud Shell에는 사전 설치된 툴킷 외에도 표준 unix CLI (명령 줄 인터페이스) 도구 및nano와 같은 텍스트 편집기가 함께 제공됩니다.Cloud Shell에서 바로 파일을 만들고 편집 할 수 있습니다.
AutoML Vision은 ML 전문 지식이 부족한 개발자가 고품질 이미지 인식 모델을 교육하는 데 도움이됩니다.AutoML UI에 이미지를 업로드하면 사용하기 쉬운 REST API를 통해 예측을 생성하기 위해 GCP에서 즉시 사용할 수있는 모델을 학습 할 수 있습니다.
이 실습에서는 이미지를 Cloud Storage에 업로드하고이를 사용하여 다양한 유형의 구름 (적운, 적란운 등)을 인식하도록 사용자 지정 모델을 학습합니다.
당신이 배울 것
라벨이 지정된 데이터 세트를 Google Cloud Storage에 업로드하고 CSV 라벨 파일을 사용하여 AutoML Vision에 연결합니다.
AutoML Vision으로 모델을 교육하고 정확도를 평가하십시오.
훈련 된 모델에서 예측을 생성합니다.
Google Cloud Shell 활성화
Google Cloud Shell은 개발 도구가로드 된 가상 머신입니다.영구적 인 5GB 홈 디렉토리를 제공하며 Google 클라우드에서 실행됩니다.Google Cloud Shell은 GCP 리소스에 대한 명령 줄 액세스를 제공합니다.
GCP 콘솔의 오른쪽 상단 툴바에서 Open Cloud Shell 버튼을 클릭합니다.
계속을클릭하십시오.
환경을 프로비저닝하고 연결하는 데 약간의 시간이 걸립니다.연결되면 이미 인증되었으며 프로젝트는PROJECT_ID로 설정됩니다.예를 들면 다음과 같습니다.
gcloud는 Google Cloud Platform 용 명령 줄 도구입니다.Cloud Shell에 사전 설치되어 제공되며 탭 완성을 지원합니다.
이 명령으로 활성 계정 이름을 나열 할 수 있습니다.
gcloud auth list
AutoML Vision 설정
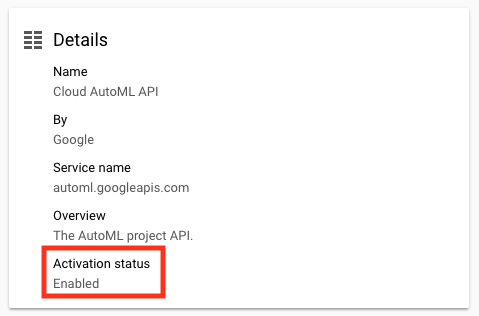
AutoML Vision은 이미지 분류 모델을 훈련시키고 예측을 생성하는 모든 단계에 대한 인터페이스를 제공합니다.Cloud AutoML API를 활성화하여 시작하십시오.
탐색 메뉴를 열고API 및 서비스>라이브러리를선택하십시오.검색 창에 "Cloud AutoML API"를 입력하십시오.온 클릭클라우드 AutoML의 API의결과 다음 클릭사용.
1 분 정도 걸릴 수 있습니다.이제 다음 페이지에 있어야합니다 (활성화 상태가Enabled로 설정되어 있는지 확인하십시오).
진행 상황 확인을클릭하여 목표를 확인하십시오
이제 새 탭을 열고AutoML UI로이동하십시오.랩 자격 증명을 선택하고허용을클릭하여 로그인합니다.
Chrome 사용자를위한 참고 사항 :이 페이지가 표시되지 않으면 현재 Chrome 사용자 프로필에서 로그 아웃 한 후 다시 열어보십시오.
Google Cloud 프로젝트를 지정하라는 메시지가 표시됩니다.드롭 다운 메뉴에서 Qwiklabs 프로젝트 ID를 선택하고계속을클릭하십시오.
지금 설정버튼을클릭하십시오.시간이 조금 걸립니다.
GCP 콘솔로 돌아갑니다.Cloud Shell에서이 명령을 복사하여 프로젝트 ID 및 Qwiklabs Username에 대한 환경 변수를 작성<QWIKLABS_USERNAME>하고 실험실에 로그인 한 사용자 이름으로 바꾸십시오.
구름의 이미지를 분류하기 위해 모델을 훈련 시키려면 모델이 다른 유형의 구름과 관련된 이미지 기능에 대한 이해를 개발할 수 있도록 레이블이 지정된 훈련 데이터를 제공해야합니다.이 예제에서 모델은 3 가지 다른 유형의 구름, 권운, 적운 및 적란운을 분류하는 방법을 배웁니다.AutoML Vision을 사용하려면 훈련 이미지를 Google Cloud Storage에 넣어야합니다.
GCP 콘솔에서탐색 메뉴를열고저장소>브라우저를선택하십시오.
일단 거기에 도달하면 마지막 단계에서 생성 한 버킷이 표시됩니다.
클라우드 이미지를 추가하기 전에 Cloud Shell에서 다음 명령을 실행하고 아래 명령에서 버킷 이름으로 바꾸어 버킷 이름으로 환경 변수를 생성YOUR_BUCKET_NAME하십시오.
export BUCKET=YOUR_BUCKET_NAME
교육 이미지는 Cloud Storage 버킷에서 공개적으로 사용할 수 있습니다.gsutilCloud Storage 용 명령 줄 유틸리티를사용하여교육 이미지를 버킷에 복사하십시오.
이미지 복사가 완료되면Cloud Storage 브라우저 상단의새로 고침버튼을클릭하십시오.그런 다음 버킷 이름을 클릭하십시오.분류 할 3 가지 서로 다른 클라우드 유형 각각에 대해 3 개의 사진 폴더가 표시되어야합니다.
각 폴더에서 개별 이미지 파일을 클릭하면 각 클라우드 유형에 대해 모델을 학습하는 데 사용할 사진을 볼 수 있습니다.
데이터 세트 만들기
교육 데이터가 Cloud Storage에 있으므로 AutoML Vision에서 액세스 할 수있는 방법이 필요합니다.각 행에 학습 이미지의 URL과 해당 이미지의 관련 레이블이 포함 된 CSV 파일을 만듭니다.이 CSV 파일은 귀하를 위해 작성되었습니다.버킷 이름으로 업데이트하면됩니다.
다음 명령을 실행하여 파일을 Cloud Shell 인스턴스에 복사하십시오.
gsutil cp gs://automl-codelab-metadata/data.csv .
그런 다음 프로젝트의 파일로 CSV를 업데이트하십시오.
sed -i -e "s/placeholder/${BUCKET}/g" ./data.csv
이제이 파일을 Cloud Storage 버킷에 업로드 할 준비가되었습니다.
gsutil cp ./data.csv gs://${BUCKET}
해당 명령이 완료되면버킷 새로 고침버튼을클릭하십시오.data.csv버킷에 파일이 있는지 확인하십시오.
AutoML Vision탭으로다시 이동하십시오.여전히 "Google 클라우드 프로젝트 설정 완료"상태 인 경우다시 확인을클릭하십시오.
이제 페이지가 다음과 유사해야합니다.
이전 버전 일 수 있으니 아래 이미지 참고
콘솔 상단에서+ NEW DATASET을클릭하십시오.
데이터 세트 이름으로 "clouds"를 입력하십시오.
Cloud Storage에서 CSV 파일선택을선택하고방금 업로드 한 파일의 URL에 파일 이름을 추가하십시오gs://your-project-name-vcm/data.csv.
이 실습에서는 "다중 라벨 분류 사용"을 선택하지 마십시오.자신의 프로젝트에서다중 클래스 분류를수행하는 경우이 확인란을 선택하고 싶을 수 있습니다.
데이터 세트 작성을선택하십시오.
이미지를 가져 오는 데 약 2 분이 걸립니다.가져 오기가 완료되면 데이터 세트의 모든 이미지가 포함 된 페이지가 나타납니다.
진행 상황 확인을확인
이미지 검사
가져 오기가 완료되면 이미지 탭으로 이동합니다.
왼쪽 메뉴에서 다른 레이블 (예 : 적운 클릭)로 필터링하여 교육 이미지를 검토하십시오.
참고 : 프로덕션 모델을 구축하는 경우 높은 정확도를 보장하기 위해
레이블 당 최소 100 개의 이미지가 필요합니다.
이것은 단지 데모 일 뿐이므로 20 개의 이미지 만 사용되므로 모델을 빠르게 학습 할 수 있습니다.
이미지에 잘못 레이블이 지정된 경우 이미지를 클릭하여 레이블을 전환하거나 학습 세트에서 이미지를 삭제할 수 있습니다.
각 라벨에 몇 개의 이미지가 있는지에 대한 요약을 보려면LABEL STATS를클릭하십시오.브라우저 왼쪽에 다음이 표시됩니다.
참고 : 아직 레이블이 지정되지 않은 데이터 세트로 작업중인 경우
AutoML Vision은 사내 휴먼 레이블링 서비스를 제공합니다.
모델 훈련
모델 훈련을 시작할 준비가되었습니다!AutoML Vision은 모델 코드를 작성할 필요없이 자동으로이를 처리합니다.
당신의 구름 모델을 학습하기 위해, 이동기차탭을 클릭시작 훈련.
모델 이름을 입력하거나 기본 자동 생성 이름을 사용하십시오.
남겨클라우드 호스팅을 선택하고 클릭시작 훈련.
이는 작은 데이터 세트이므로완료하는데 약5 분이걸립니다.
모델 평가
에서평가탭, 당신은 모델의 정밀도 및 호출에 대한 정보를 볼 수 있습니다.다음과 유사해야합니다.
당신은 또한점수 임계 값으로놀 수 있습니다:
마지막으로 아래로 스크롤하여Confusion 매트릭스를봅니다.
이 모든 것은 모델 정확도를 평가하고 교육 데이터를 개선 할 수있는 위치를 확인할 수있는 일반적인 머신 러닝 메트릭을 제공합니다.이 실습에서는 정확도에 중점을 두지 않았으므로 예측 섹션에 대한 다음 섹션으로 넘어갑니다.직접 정확도 측정 항목을 찾아보세요.
예측 생성
이제 가장 중요한 부분이되었습니다 : 이전에는 보지 못한 데이터를 사용하여 훈련 된 모델에 대한 예측 생성.
AutoML UI에서예측탭으로이동하십시오.
예측을 생성하는 몇 가지 방법이 있습니다.이 실습에서는 UI를 사용하여 이미지를 업로드합니다.모델이이 두 이미지를 분류하는 방법을 볼 수 있습니다 (첫 번째는 권운, 두 번째는 적란운입니다).
이 이미지들을 각각 마우스 오른쪽 버튼으로 클릭하여 로컬 컴퓨터로 다운로드하십시오.
AutoML Vision UI로 돌아가서이미지업로드를클릭하고 클라우드를 온라인 예측 UI에 업로드하십시오.예측 요청이 완료되면 다음과 같은 내용이 표시됩니다.
진행 상황 확인 - pedictions를 실행
매우 멋지다-모델은 각 구름 유형을 올바르게 분류했습니다!
축하합니다!
웹 UI를 통해 사용자 정의 기계 학습 모델을 학습하고 예측을 생성하는 방법을 배웠습니다.이제 자신의 이미지 데이터 세트에서 모델을 훈련하는 데 필요한 것을 얻었습니다.무엇을 다루 었는가
Cloud Storage에 교육 이미지를 업로드하고 이러한 이미지를 찾기 위해 AutoML Vision 용 CSV를 생성하십시오.
Google Cloud Speech API를 사용하면 Google 음성 인식 기술을 개발자 응용 프로그램에 쉽게 통합 할 수 있습니다.Speech API를 사용하면 서비스에서 오디오를 보내고 텍스트를받을 수 있습니다 (자세한내용은 Google Cloud Speech API 란 무엇입니까?참조).
당신이 할 일
API 키 생성
음성 API 요청 만들기
음성 API 요청을 호출
설정 및 요구 사항
Google Cloud Shell
Google Cloud Shell 활성화
Google Cloud Shell은 개발 도구가로드 된 가상 머신입니다.영구적 인 5GB 홈 디렉토리를 제공하며 Google 클라우드에서 실행됩니다.Google Cloud Shell은 GCP 리소스에 대한 명령 줄 액세스를 제공합니다.
GCP 콘솔의 오른쪽 상단 툴바에서 Open Cloud Shell 버튼을 클릭합니다.
계속을클릭하십시오.
환경을 프로비저닝하고 연결하는 데 약간의 시간이 걸립니다.연결되면 이미 인증되었으며 프로젝트는PROJECT_ID로 설정됩니다.예를 들면 다음과 같습니다.
gcloud는 Google Cloud Platform 용 명령 줄 도구입니다.Cloud Shell에 사전 설치되어 제공되며 탭 완성을 지원합니다.
API 키 생성
curlSpeech API에 요청을 보내는 데사용하므로요청 URL을 전달할 API 키를 생성해야합니다.
API 키를 작성하려면탐색 메뉴>API 및 서비스>신뢰 정보를클릭하십시오.
그런 다음신뢰 정보 작성을클릭하십시오.
드롭 다운 메뉴에서API 키를선택하십시오.
방금 생성 한 키를 복사하십시오.
이제 API 키가 있으므로 각 요청에 API 키 값을 삽입하지 않아도되도록 환경 변수로 저장합니다.
다음 단계를 수행하려면 ssh를 통해 프로비저닝 된 인스턴스에 연결하십시오.탐색 메뉴를 열고Compute Engine을선택하십시오.다음과 같은 프로비저닝 된 Linux 인스턴스가 표시되어야합니다.
SSH 버튼을 클릭하십시오.대화식 쉘로 이동합니다.명령 행에<YOUR_API_KEY>방금 복사 한 키로다음을 입력하십시오.
export API_KEY=<YOUR_API_KEY>
나머지 실습을 위해이 SSH 세션을 유지하십시오.
Speech API 요청 만들기
참고 :Google Cloud Storage에서 사용 가능한 사전 기록 된 파일을 사용합니다gs://cloud-samples-tests/speech/brooklyn.flac.당신은 음성 API로 전송하기 전에이 파일을들을 수 있습니다여기에.
request.jsonSSH 명령 행에서작성하십시오.이를 사용하여 음성 API에 대한 요청을 작성합니다.
touch request.json
이제 열request.json사용하여 원하는 명령 줄 편집기 (nano,vim,emacs) 또는gcloud.샘플 원시 오디오 파일request.json의uri값을사용하여파일에다음을 추가하십시오.
{
"results": [
{
"alternatives": [
{
"transcript": "how old is the Brooklyn Bridge",
"confidence": 0.98267895
}
]
}
]
}
이transcript값은 음성 파일의 오디오 파일 텍스트 녹음을 반환하며confidenceAPI가 오디오를 정확하게 녹음했는지 확인합니다.
syncrecognize위 요청에서메소드를 호출했음을 알 수 있습니다.Speech API는 동기식 및 비동기식 음성 텍스트 변환을 모두 지원합니다.이 예제에서는 완전한 오디오 파일을 보냈지 만syncrecognize, 사용자가 여전히 말하고있는 동안이 방법을사용하여텍스트 음성을 텍스트 음성으로 스트리밍할 수 있습니다.
Speech API 요청을 만든 다음 Speech API를 호출했습니다.다음 명령을 실행하여 응답을result.json파일에 저장하십시오.
Google Cloud Natural Language API를 사용하면 텍스트 문서, 뉴스 기사 또는 블로그 게시물에 언급 된 사람, 장소, 이벤트 등에 대한 정보를 추출 할 수 있습니다.이 도구를 사용하여 소셜 미디어에서 제품에 대한 감정을 이해하거나 콜 센터 또는 메시징 앱에서 발생하는 고객 대화의 의도를 분석 할 수 있습니다.분석을 위해 텍스트 문서를 업로드 할 수도 있습니다.
Cloud Natural Language API 기능
구문 분석 :토큰과 문장을 추출하고 품사 (PoS)를 식별하며 각 문장에 대한 종속성 구문 분석 트리를 만듭니다.
엔티티 인식 :개인, 조직, 위치, 이벤트, 제품 및 미디어와 같은 유형별로 엔티티를 식별하고 레이블을 지정하십시오.
감정 분석 :텍스트 블록으로 표현 된 전체 감정을 이해합니다.
컨텐츠 분류 :사전 정의 된 700 개 이상의 카테고리로 문서를 분류하십시오.
다국어 :영어, 스페인어, 일본어, 중국어 (간체 및 번체), 프랑스어, 독일어, 이탈리아어, 한국어 및 포르투갈어를 포함한 여러 언어로 텍스트를 쉽게 분석 할 수 있습니다.